I am Creating a Disaster Recovery Site for My Home Lab

Most will say home labs are generally over the top, with server-grade hardware in server racks. And I think I agree for the most part. However, most of us do what we do because we love tinkering around with technology and cool software/hardware. In my transition down to mini PCs in the home lab, which is an in-flight project I am underway in at the moment, I will have spare hardware that will be available for use or to sell. In thinking through everything, I am thinking of creating a Disaster Recovery Site in my shop building that is outside of my home where my home lab resides. Let’s walk through what I have planned. I would like to get everyone’s take on the plans and your thoughts on how you can back up and plan for disaster with your self-hosted services.
Table of contents
What is a Disaster Recovery Site?
DR stands for “disaster recovery” and is part of how enterprises help to protect critical data from catastrophic loss in the event of a partial or total site failure. Most enterprise organizations follow a traditional data protection methodology called the “3-2-1 data protection model” or some modified form of it for protecting their data.
It calls for having at least (3) copies of your data stored on (2) different kinds of media, with at least (1) copy stored “offsite”. The offsite portion is where a DR facility comes into play.
What technologies are involved with a Disaster Recovery Site facility?
Generally speaking, when you have a DR facility, you are using “replication” jobs to create exact replicas of your virtual machines in your DR facility. In the event of a site failure or disaster, the replica VMs can be spun up and assume workloads and application traffic.
You can use something like the built-in Proxmox replication functionality, or you can use Site Recovery Manager with VMware or third-party solutions like Veeam, BDRSuite by Vembu, or NAKIVO.
Third-party tools can replicate virtual machines between sites and automate and provide orchestration for the failover and fallback process if a site goes down.
This is a key piece since the network reconfiguration can be tedious without some type of automation or orchestration.
In my case, the main purpose of the DR site is not to failover, so to speak, if I have some type of major disaster like a fire. Instead, it is to have a copy of critical data.
What “sites” am I using?
These days for replication, replicating copies of your data from on-premises to the cloud is extremely popular and beneficial. I am doing that for some of my data. However, I have a separate shop building from my home that I can take advantage of if I were to have a true disaster like a fire in my home or something else that totally wipes out my data.
Take a look at the high-level overview of my plan for replication:
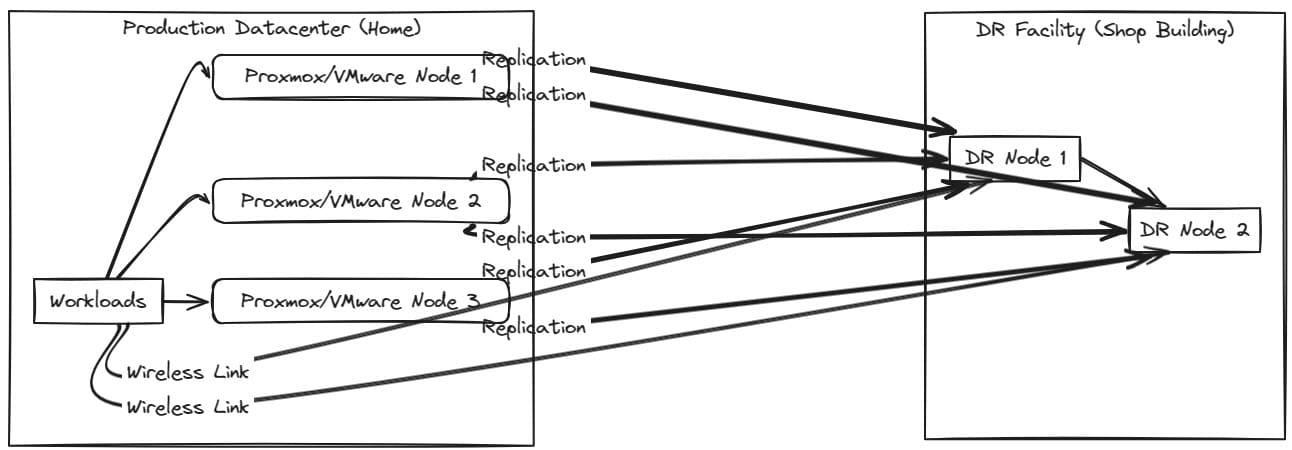
The shop building already has a network rack where I am extending several layer 2 segments along with wireless connectivity. I plan to mount a new wall mount rack above or to the side of the existing rack and house 1 or 2 servers as the target of replication jobs.
As I migrate my “production” datacenter over to mini PCs, I will have spare older supermicro servers that can be used for this purpose.
Disregard the mess of cabling in the rack. Another project I have on the schedule is getting this cleaned up and looking better.

Also, while I would like to have fibre connectivity between the house and the shop building in the future, I currently have a wireless bridge that connects the shop with the house. I am using the Ubiquiti Nanobeam 5AC units.

What about power savings?
You may wonder, with the plan to move most of the production data center to mini PCs, won’t I simply be reintroducing the more power-hungry servers that I am working to replace? This is true; the supermicro servers will need to be powered up for the replication jobs.
However, I plan to do some power automation, which I have written about and created a video about. I orchestrate powering on and powering off the Supermicro servers using the IPMI controller. I can schedule powering these up before the replication jobs kick off.
Then, I can power these down after the replication job window. So, the less power efficient servers won’t be running all the time, since this will not be needed.
Take a look at the video here:
What are my next steps?
The order of operations for the plan involves the following:
- Continue and fully decommission Supermicro servers to be housed in the DR/shop location
- Clean up the existing network rack
- Mount a new rack to house the Supermicros
- Create replication jobs in Proxmox or VMware to send over the data
- Create power automation to power on and off the Supermicro servers before and after the replication jobs
Is creating a Disaster Recovery Site for everyone?
A separate Disaster Recovery Site for you may not be an answer. First of all, for it to really be effective, you need to have a separate physical building. This allows you to effectively withstand a disaster without having equipment destroyed with the same disaster that takes down your production datacenter.
I just happen to have a separate building with network connectivity established, so I have the building blocks to do this already. Wouldn’t cloud be better? There are certainly benefits to using cloud targets as a Disaster Recovery Site. However, for me, I have more data than I want to house in the cloud or have the budget to do. Also, restoring from a disaster from an on-premises data center for me will be much quicker since I have a copy of the data locally.
Also, a DR site like this is just another “layer” of protection in an overarching DR strategy. I will still have copies of my data that is most critical in the cloud from a few servers. However, having the additional site will allow a larger bulk of data to be effectively protected and also will provide a much quicker restore operation if there is a true disaster, like a fire.
Let me know in the comments. Are you already doing something like this?



