It feels like we have come full circle as Kubernetes has matured and has been greatly extended over the past few years to do some really amazing things. One of the amazing things you can do now with Kubernetes is run virtual machines. Kubevirt makes this possible. In this post, Let’s look at Kubevirt and this functionality.
Table of contents
What is Kubevirt?
Let’s talk about Kubevirt and what it is exactly. Kubevirt is an open source solution that allows Kubernetes clusters to run and manage virtual machines, including Linux and Windows along with native Kubernetes container workloads (pods) and allows developers to rapidly containerize applications. Enterprises are looking at ways to standardize their infrastructure and use consistent tooling. Using Kubernetes for containers and virtual machines helps with this effort.

Kubevirt provides a virtualization API, allowing the Kubernetes API to control both containers and multiple virtual machines, providing a single unified development platform for both. Kubevirt is part of the cloud native computing foundation and has many contributors from the community.
Why might developers want to use Kubevirt?
For development teams transitioning to Kubernetes infrastructure and cloud computing, especially those with existing virtual machine (VM)-based workloads with guest operating system installs that are not easy to containerize. KubeVirt bridges the gap between traditional VM configurations and modern containerized environments for development workflows to production. With Kubevirt, you no longer need a separate hypervisor environment to run your virtual machine workloads. It also allows for interacting with your Kubernetes resources using standard tools like kubectl.
Kubevirt technology addresses a smoother and quicker transition for teams with virtual machine-based workflows to rapidly containerize virtualized workloads. It allows teams to use existing virtual machines VMs for applications as they work on a strategy to deploy applications residing on container-based architectures.
Kubevirt architecture
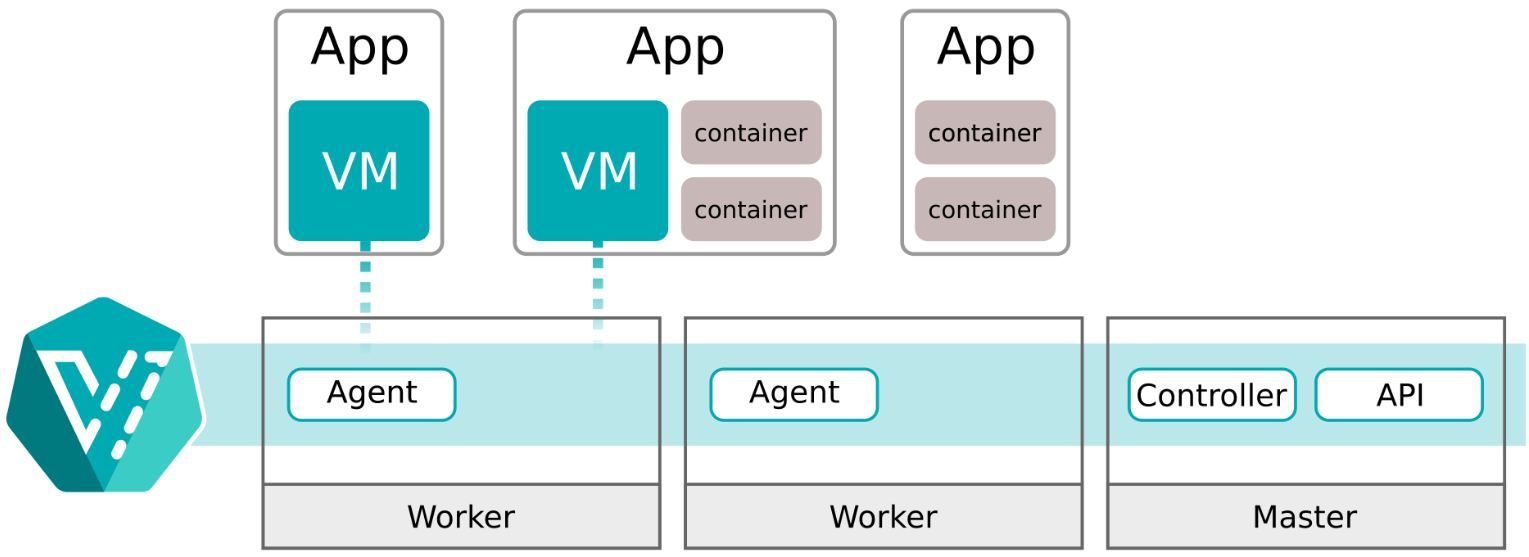
Users interacting with virtualization services communicate via the Virtualization API to arrange the desired Virtual Machine Instances (VMIs). With Kubevirt, Kubernetes is responsible for managing scheduling, networking, and storage of data for your virtual machines.
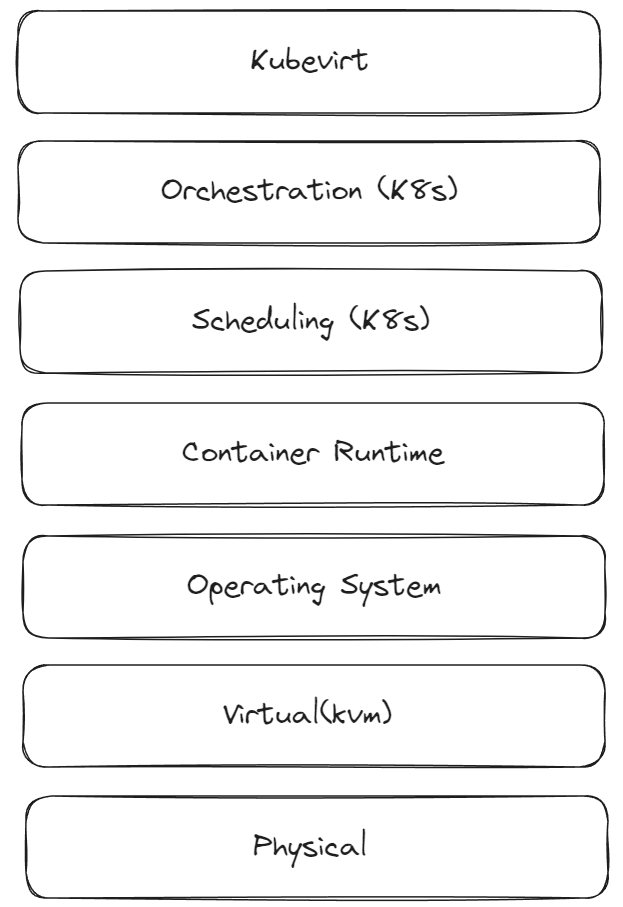
The following is a simplified diagram showing the basics of how the additional controllers and daemons communicate with Kubernetes and where the additional types are stored. Kubevirt’s architecture integrates with existing Kubernetes clusters, leveraging remaining virtualized components. This integration is made possible by the Kubevirt Operator and Custom Resource Definitions (CRDs) that extend Kubernetes capabilities.
How can you use Kubevirt?
There are multiple Kubernetes distros that you can use to try out Kubevirt and provide your feedback to the solutions. Note the following quickstart guides provided by Kubevirt.io:
Rancher Harvester: Easy Kubevirt
Also, if you want a dedicated solution for trying out Kubevirt in an easy way, Rancher Harvester is an open-source solution, containing all the packages needed to run the Kubevirt software that allows you to install Harvester on physical servers or nested virtual machines. It provides virtual machine management along with running native Kubernetes pods and pulling container images from the container registry.
Using Kubevirt with Harvester, you can run your VMs with the scalability, security, rbac, and performance constructs for your workload environment, the same as you can with your container pods. You can take a look at the Harvester project and documentation here: Harvester – Open-source hyperconverged infrastructure (harvesterhci.io). You can also check out the official repositories and releases here: GitHub – harvester/harvester: Open source hyperconverged infrastructure (HCI) software.
Below, I have booted the Harvester ISO and creating a new Harvester cluster on your nodes.
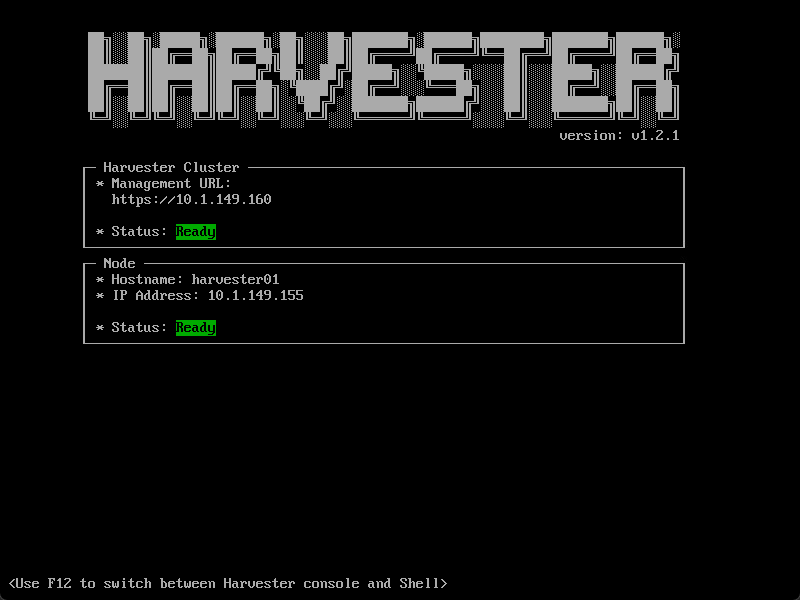
After installing Rancher Harvester and waiting for the Harvester cluster and management IP to be ready.
Logging into Harvester.
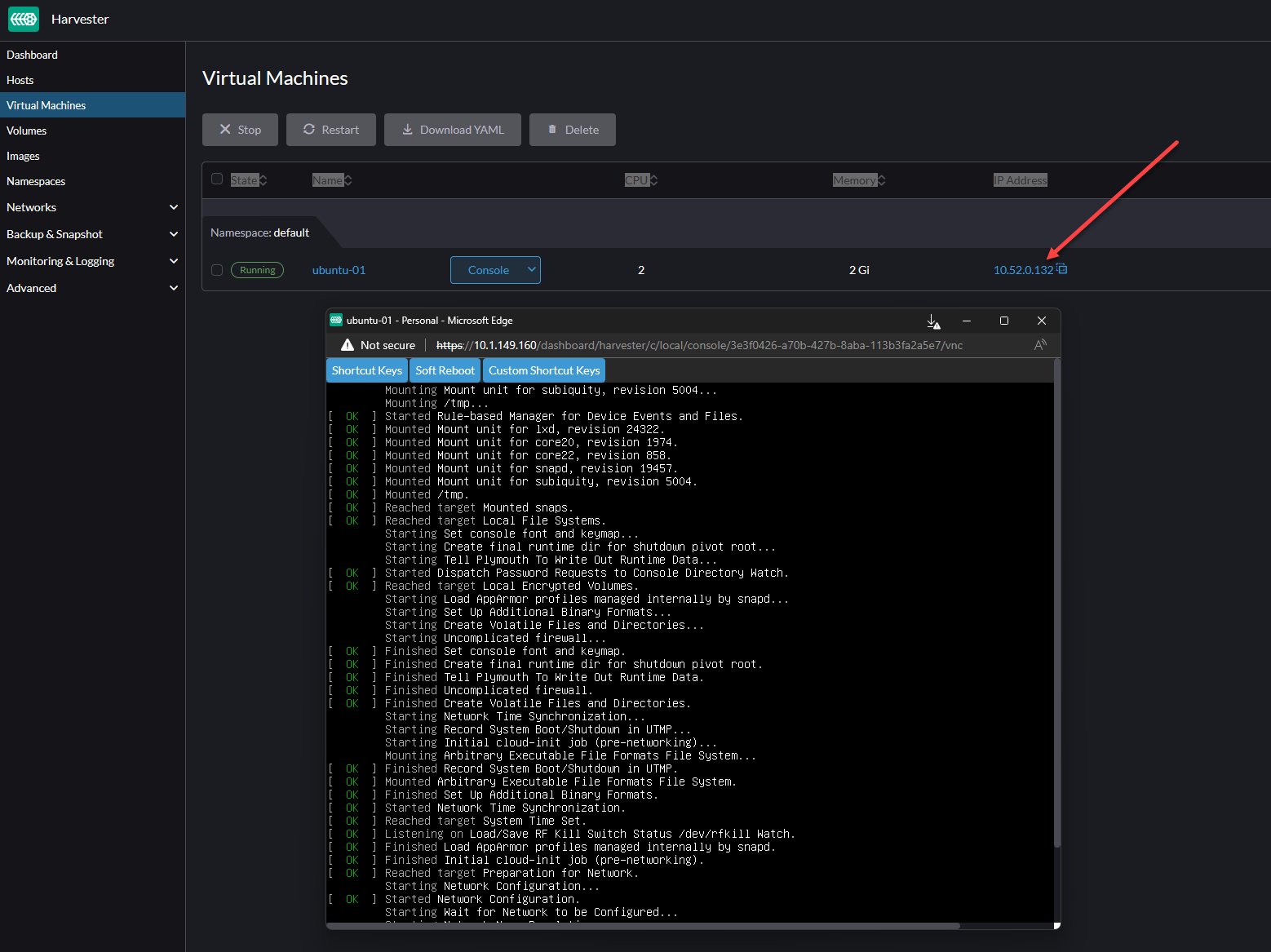
Below, I have created a new Ubuntu 22.04 virtual machine and booting the VM for installation using Kubevirt in Harvester. Very cool! The management experience in Harvester is great.
YAML file configuration for Kubevirt virtual machine
One of the really cool things about using Kubevirt to create virtual machines is the ability to describe them in a YAML file. Creating an Ubuntu 22.04 LTS VM in Harvester, I had the following YAML code for the VM manifest as an example in the above demo:
apiVersion: kubevirt.io/v1
kind: VirtualMachine
metadata:
annotations:
harvesterhci.io/vmRunStrategy: RerunOnFailure
harvesterhci.io/volumeClaimTemplates: >-
[{"metadata":{"name":"ubuntu-01-disk-0-fhsec","annotations":{"harvesterhci.io/imageId":"default/image-675pg"}},"spec":{"accessModes":["ReadWriteMany"],"resources":{"requests":{"storage":"20Gi"}},"volumeMode":"Block","storageClassName":"longhorn-image-675pg"}}]
kubevirt.io/latest-observed-api-version: v1
kubevirt.io/storage-observed-api-version: v1alpha3
network.harvesterhci.io/ips: '[]'
creationTimestamp: '2024-01-21T14:45:14Z'
finalizers:
- harvesterhci.io/VMController.UnsetOwnerOfPVCs
generation: 2
labels:
harvesterhci.io/creator: harvester
harvesterhci.io/os: ubuntu
managedFields:
- apiVersion: kubevirt.io/v1alpha3
fieldsType: FieldsV1
fieldsV1:
f:metadata:
f:annotations:
f:kubevirt.io/latest-observed-api-version: {}
f:kubevirt.io/storage-observed-api-version: {}
manager: Go-http-client
operation: Update
time: '2024-01-21T14:45:15Z'
- apiVersion: kubevirt.io/v1
fieldsType: FieldsV1
fieldsV1:
f:metadata:
f:annotations:
.: {}
f:harvesterhci.io/vmRunStrategy: {}
f:harvesterhci.io/volumeClaimTemplates: {}
f:network.harvesterhci.io/ips: {}
f:finalizers:
.: {}
v:"harvesterhci.io/VMController.UnsetOwnerOfPVCs": {}
f:labels:
.: {}
f:harvesterhci.io/creator: {}
f:harvesterhci.io/os: {}
f:spec:
.: {}
f:runStrategy: {}
f:template:
.: {}
f:metadata:
.: {}
f:annotations:
.: {}
f:harvesterhci.io/sshNames: {}
f:labels:
.: {}
f:harvesterhci.io/vmName: {}
f:spec:
.: {}
f:accessCredentials: {}
f:affinity: {}
f:domain:
.: {}
f:cpu:
.: {}
f:cores: {}
f:sockets: {}
f:threads: {}
f:devices:
.: {}
f:disks: {}
f:inputs: {}
f:interfaces: {}
f:features:
.: {}
f:acpi:
.: {}
f:enabled: {}
f:machine:
.: {}
f:type: {}
f:resources:
.: {}
f:limits:
.: {}
f:cpu: {}
f:memory: {}
f:evictionStrategy: {}
f:hostname: {}
f:networks: {}
f:terminationGracePeriodSeconds: {}
f:volumes: {}
manager: harvester
operation: Update
time: '2024-01-21T14:45:36Z'
- apiVersion: kubevirt.io/v1alpha3
fieldsType: FieldsV1
fieldsV1:
f:status:
.: {}
f:conditions: {}
f:created: {}
f:printableStatus: {}
f:ready: {}
f:volumeSnapshotStatuses: {}
manager: Go-http-client
operation: Update
subresource: status
time: '2024-01-21T15:03:12Z'
name: ubuntu-01
namespace: default
resourceVersion: '538511'
uid: 3e3f0426-a70b-427b-8aba-113b3fa2a5e7
spec:
runStrategy: RerunOnFailure
template:
metadata:
annotations:
harvesterhci.io/sshNames: '[]'
creationTimestamp: null
labels:
harvesterhci.io/vmName: ubuntu-01
spec:
affinity: {}
domain:
cpu:
cores: 2
sockets: 1
threads: 1
devices:
disks:
- bootOrder: 1
cdrom:
bus: sata
name: disk-0
- disk:
bus: virtio
name: cloudinitdisk
inputs:
- bus: usb
name: tablet
type: tablet
interfaces:
- macAddress: 52:54:00:de:68:02
masquerade: {}
model: virtio
name: default
features:
acpi:
enabled: true
machine:
type: q35
memory:
guest: 1948Mi
resources:
limits:
cpu: '2'
memory: 2Gi
requests:
cpu: 125m
memory: 1365Mi
evictionStrategy: LiveMigrate
hostname: ubuntu-01
networks:
- name: default
pod: {}
terminationGracePeriodSeconds: 120
volumes:
- name: disk-0
persistentVolumeClaim:
claimName: ubuntu-01-disk-0-fhsec
- cloudInitNoCloud:
networkDataSecretRef:
name: ubuntu-01-ixwie
secretRef:
name: ubuntu-01-ixwie
name: cloudinitdisk
status:
conditions:
- lastProbeTime: null
lastTransitionTime: '2024-01-21T15:03:09Z'
status: 'True'
type: Ready
- lastProbeTime: null
lastTransitionTime: null
status: 'True'
type: LiveMigratable
created: true
printableStatus: Running
ready: true
volumeSnapshotStatuses:
- enabled: false
name: disk-0
reason: 2 matching VolumeSnapshotClasses for longhorn-image-675pg
- enabled: false
name: cloudinitdisk
reason: Snapshot is not supported for this volumeSource type [cloudinitdisk]
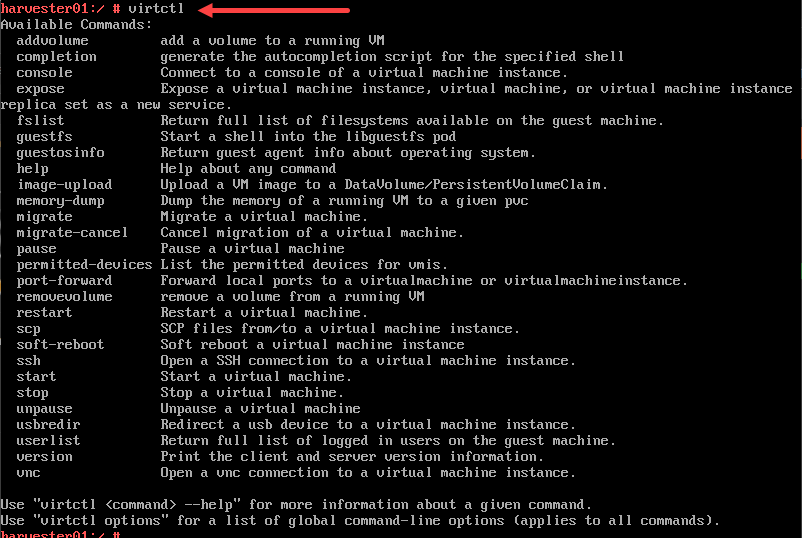
Using the virtctl command line interface
You can also interact with your Kubevirt virtual machines using the virtctl command line tool. You may need to install virtctl. However, in working with Harvester, it is installed by default.
Note the following commands:
- addvolume – add a volume to a running VM
- completion – generate the autocompletion script for the specified shell
- console – connect to a console of a virtual machine instance
- expose – expose a virtual machine instance, virtual machine, or virtual machine instance replica set as a new service
- fslist – return full list of filesystems available on the guest machine
- guestfs – start a shell into the libguestfs pod
- guestosinfo – return guest agent info about operating system
- help – help about any command
- image-upload – upload a VM image to a DataVolume/PersistentVolumeClaim
- memory–dump – dump the memory of a running VM to a given pvc
- migrate – migrate a virtual machine
- migrate–cancel – cancel migration of a virtual machine
- pause – pase a virtual machine
- permitted–devices – list the permitted devices for vmis
- port–forward – forward local ports toa virtualmachine or virtualmachineinstance
- removevolume – remove a volume from a running VM
- restart – restart a virtual machine
- scp – scp files from/to a virtual machine instance
- soft–reboot – soft reboot a virtual machine instance
- ssh – open a SSH connection to a virtual machine instance
- start – start a virtual machine
- stop – stop a virtual machine
- unpause – unpause a virtual machine
- usbredir – redirect a USB device to a virtual machine instance
- userlist – return full list of logged in users on the guest machine
- version – print the client and server version information
- vnc – open a vnc connection to a virtual machine instance
Wrapping up Kubevirt as an excellent tool in the Kubernetes Ecosystem
In this introduction blog to Kubevirt, we have seen it is an interesting and powerful tool when running Kubernetes environments. It allows a company to harness the power of modern applications in Kubernetes pods and virtual machines on top of the Kubernetes cluster node for all their virtualization needs. This makes Kubernetes not just an environment for containers, but also for VMs.
Since it uses the Kubernetes API, developers, and DevOps engineers can use the powerful Kubernetes APIs in order to automate many aspects of the environment, including policies, and apply these same API endpoints for automating their virtual machine operations. Since running Kubernetes is getting more and more interesting and used by organizations around the world, I am wondering how many are interested in migrating away from traditional hypervisors and using Kubernetes for everything. If you have already migrated VMs to Kubernetes what results have you see and what issues have you ran into? Are you using this or interested in using this at the core or edge? Is there a feature you are missing between Kubevirt and traditional hypervisor products? Let me know in the comments or in the forums.
Google is updating how articles are shown. Don’t miss our leading home lab and tech content, written by humans, by setting Virtualization Howto as a preferred source.
About The Author