Network Best Practices for vSphere HA High Availability Clusters
One of the basic features that is built into the VMware vSphere solution when virtualizing your workloads on top of a vSphere cluster is high-availability. In fact, VMware HA is found at the Essentials Plus license level and higher. If you are not using it, you should be. Aside from simply turning on the VMware HA feature on a vSphere cluster, there are other network best practices for vSphere HA high availability clusters you want to take a look at. What are those? Let’s dive into a few of the network best practices when working with VMware HA.
What is vSphere HA?
What is vSphere HA? As a brief primer on VMware HA, it provides high availability in your vSphere cluster by pooling the virtual machines and hosts they reside on into a cluster. The individual cluster hosts are monitored. When there is a failure of a host for whatever reason, the virtual machines on a failed host are restarted on healthy hosts remaining in the vSphere cluster.
When vSphere HA is configured on a vSphere cluster, one host is elected as the master host. This master host is responsible for communicating with vCenter Server and monitors the other ESXi hosts in the cluster as well as virtual machines that are protected by vSphere HA. There are three “failure” types that vSphere HA handles in unique ways:
- Failed host – host goes down
- Network Partition = Host isn’t isolated on the network but is not able to communicate over the network to the vSphere HA master host
- Network Isolated – the host becomes network isolated
Determining the vSphere HA Failure Type
Failed – No heartbeats are received from the subordinate host, no heartbeats are being exchanged with any datastores, no pings are being responded to when sent to the management IP address
Network Partition – Datastore heartbeats from a host are observed, but the vSphere HA master cannot see the subordinate host via the network.
Network isolated – Host is still running but no traffic is observed from the vSphere HA agents on the management network. Attempts are made to ping the cluster isolation addresses. If these fail, the host declares that it is isolated from the network.
vSphere Proactive HA
The new proactive HA feature in recent vSphere releases allows for proactively performing HA actions when a component on an ESXi host fails (i.e. host power supply, etc). Whent his happens you can automate the HA response such as vMotioning the VMs over to a healthy host.
Network Best Practices for vSphere HA High Availability Clusters
Let’s take a look at network best practices for vSphere HA high availability clusters and see how you can implement recommended best practices in the arena of networking.
vSphere HA Networking Best Practices
There are many considerations to be made around the vSphere networking. The vSphere HA component relies heavily on the networking between the ESXi hosts in the vSphere cluster to determine the various states of the hosts and which actions need to be taken in the different failure states.
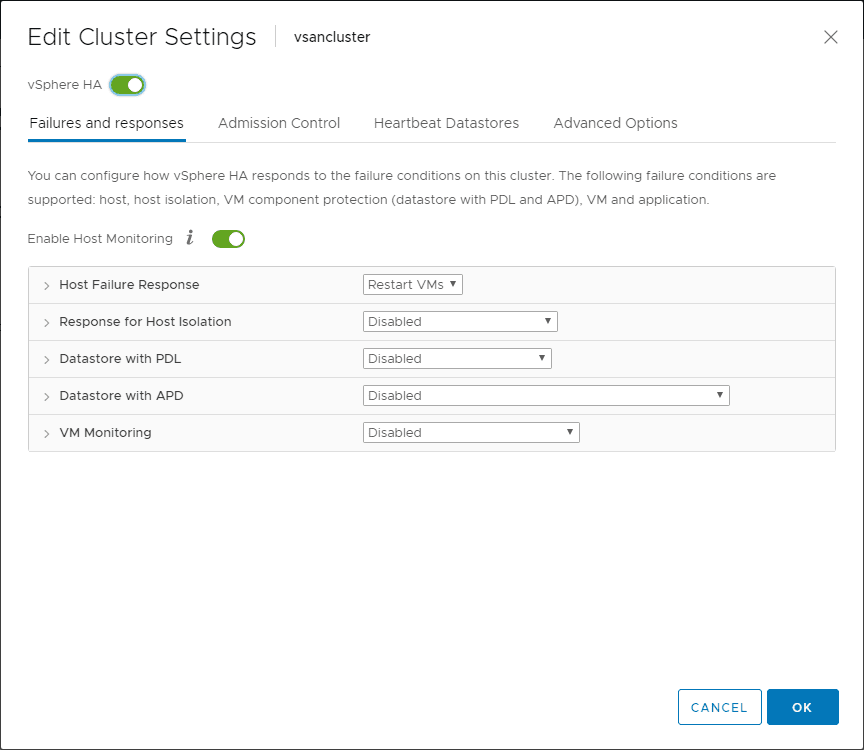
There are network considerations you need to make with vSphere HA when performing maintenance on ESXi hosts in a vSphere cluster. When you have vSphere HA turned “On” for a cluster, you can actually cuase the detection of failed hosts and network isolation due to heartbeat traffic not working correctly.
If you are performing maintenance on your ESXi hosts in the realm of network changes, suspend vSphere HA monitoring for that particular host. If you do not, you could inadvertently cause an unwanted attempt to fail over your VMs to a different host in the vSphere cluster.
Before making changes on your vSphere hosts in the cluster, disable HA for the cluster, make the network changes, and then turn on vSphere HA at the cluster level again. This will reconfigure the hosts in the cluster for HA monitoring.
Which networks are used? To know which network may cause a disruption in vSphere HA, you need to identify the HA network being used for HA communications.
On ESXi hosts in a vSphere cluster, vSphere HA uses all VMkernel networks for HA communication.
Network Isolation Address Importance
What is the network isolation address? This is the special address that is used by vSphere HA to determine if a host is isolated from the network. When a host has stopped receiving heartbeats from all other hosts in the cluster, the network isolation address is pinged. If a host can ping its network isolation address, the host knows it is not isolated from the network and most likely the other hosts in the cluster have failed or are network partitioned.
If the host cannot ping the isolation address, the host most likely is isolated from the network. No failover action is taken in the network isolation scenario.
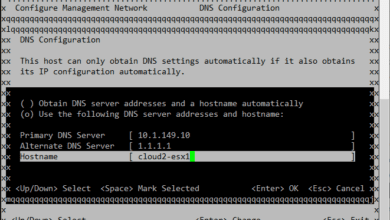
What is configured as the network isolation address by default? The default gateway. One default gateway is specified no matter how many management networks are configured. Additionally, you can use the advanced option (das.isolationaddress) to add isolation addresses for additional networks.
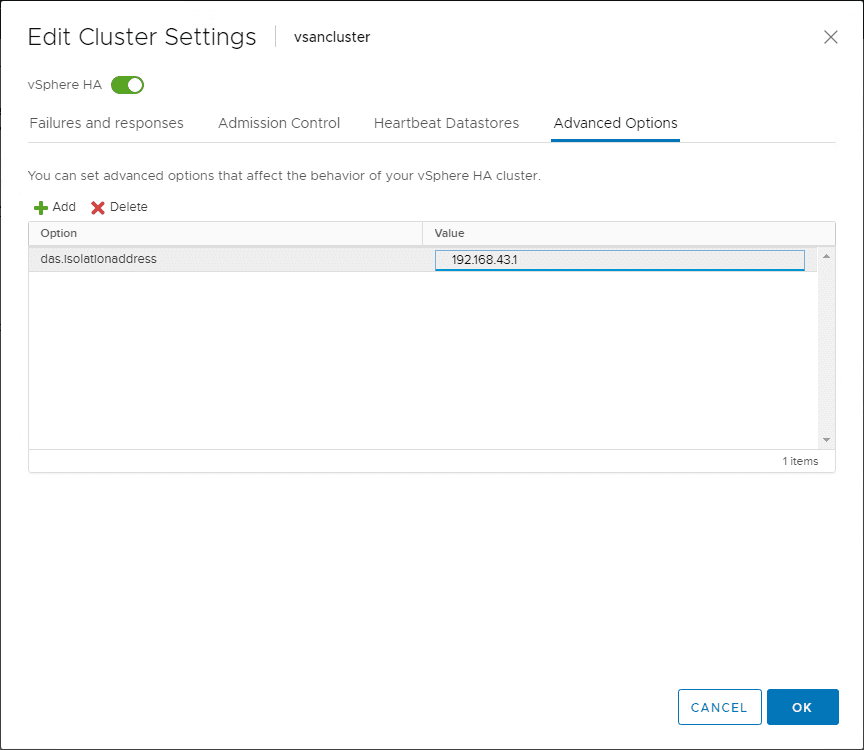
More information on HA advanced options found here: https://docs.vmware.com/en/VMware-vSphere/6.5/com.vmware.vsphere.avail.doc/GUID-E0161CB5-BD3F-425F-A7E0-BF83B005FECA.html
Das.isolationaddress option – Sets the address to ping to determine if a host is isolated from the network. This address is pinged only when heartbeats are not received from any other host in the cluster. If not specified, the default gateway of the management network is used. This default gateway has to be a reliable address that is available, so that the host can determine if it is isolated from the network. You can specify multiple isolation addresses (up to 10) for the cluster: das.isolationAddressX, where X = 0-9. Typically you should specify one per management network. Specifying too many addresses makes isolation detection take too long.
Network Path redundancy
Network path redundancy is crucially important in a vSphere cluster in all aspects. However, with the vSphere HA functionality it is critically important as well. You don’t want to have false positives when it comes to perceived HA failures due to network communication issues only.
Having multiple NICs backing a network configured on your ESXi server that are uplinked into redundant physical switches. This helps to make sure that you have redundancy in the case of NIC failures, network cable failures, network cable removal, and switch failures.
Additionally, you can also benefit from creating a second management network attached to a separate virtual switch. This creates additional redundancy for vSphere HA to communicate the heartbeats.
Wrapping Up
Network Best Practices for vSphere HA High Availability Clusters are certainly an area that needs to be given due attention when configuring, troubleshooting, and architecting a vSphere HA solution for a vSphere cluster. By keeping in line with these and other best practices mentioned, it helps to minimize problems related to network issues with vSphere HA.