Protect VMs at the Site-Level with VM Replication
We have covered various aspects of protecting your valuable business data, including effective backups as well as both VMware vSphere and Hyper-V backup best practices. By thinking about your data, and best practices for protecting it in these two very popular enterprise data center virtualization products, it will lead to very positive results from a data protection standpoint. There is another aspect to protecting your data not only from a workload perspective, but from a site-level perspective. When protecting your business, you must think about what happens when an entire site is affected or taken offline either in part, or completely. Let’s take a look at how to Protect VMs at the Site-Level with VM Replication and see how this aspect of data protection is extremely important.
Why Site-Level VM Protection is Important
When protecting your data, you must not only think about your data from a single workload perspective, files and folders, or application data. You must also think about what happens if you lose an entire production site. It may seem far fetched that an entire site could go down, especially if you have generators in case utility power is lost and redundant Internet providers for redundancy for network communication.
However, entire sites can be brought down due to major disasters that can strike that are either weather related or man-made disasters. A case in point is if you have a main production location in an area that is prone to hurricanes. There is a good chance that over the course of time, your entire site could be taken offline due to disaster related to a hurricane.
In that case, it is wise to think ahead of time of the potential of having your production facility taken offline and how you can maintain business continuity in such a case.
The consequences and disaster resulting from a natural disaster can last for quite some time. How do you get your resources back online in an effective and efficient manner? How do you keep relatively close copies of your data and infrastructure in a safe location so that you have resources on standby, ready to assume the traffic and data requests of your customers and internal business processes?
How VM Replication Protects the Site-Level
The answer to the aforementioned challenge is VM Replication. To begin with, let’s see what VM replication is and how it allows you to protect your data at the site level. VM replication is a mechanism that allows creating an exact “replica” of your production VM in another location. You can think of this as a “warm standby” location.
The replica environment is generally similar to your production infrastructure. However, your business can decide during a site-level failure what level of performance degradation is acceptable. This may allow for less powerful infrastructure to be provisioned in the DR or secondary replica environment. This is a common consideration when provisioning a replicated environment.
To begin the replication process, a full replication of the entire VM will need to be copied to the replicated environment. This is usually accomplished in a couple of ways. The copy can be completed “over the wire” as a full network copy across the WAN link, etc. Alternatively, the initial replication can be staged by using a “seed drive” where the VM is copied to removable media, physically taken to the replicated environment, copied to the DR infrastructure there, and provisioned accordingly. After either the initial full network copy or seeding of the initial copy, each replication interval copies the changes that have occurred since the last replication interval.
The efficiency of the replication process can be greatly increased by using changed block tracking included either natively in the hypervisor or as part of a third-party filter driver found in the replication solution. By tracking changes to data at the block level, each replication operation can efficiently only copy the changes that have happened since the last replication interval.
Depending on the RPO decided for the replication process, each time the replication job runs, the resulting VM and its data are brought up to date with the data housed in the production VM as of the timeframe of the replication process.
As with deciding on the RPO value of a backup job, determining the RPO of the replication job determines the amount of data the business can stand to lose if there is a site failure. Generally speaking the backup job generally stores data in the same site as the environment being protected. If you have an entire site failure, the backups are no longer helpful since it will either do no good for data to be restored or all data including backups have been lost in the production site.
At that point in time, you are relying on the replication of your data from production to the secondary location to maintain a healthy, viable copy of your data in a site location that can be brought online to service your business/customers.
How is the “switch flipped” from production to DR that has been kept up-to-date using replication?
What’s Involved with the Failover Process?
You may already be thinking of how you go from having traffic routed to one location that is serving as the production site for your workloads and then change the location altogether to shift to your secondary/DR facility for serving traffic. The process involved is known as a Failover. The failover process means that you are “flipping a switch” that says your main production environment is down. Make sure resources are powered on and ready to serve traffic in the secondary location. Then, reconfigure your DNS records to point to IPs located in the secondary location.
Obviously, there is a lot of complexity that is involved in the above to successfully shift traffic from being served at one data center location to another.
Much of the complexity that comes along with replicating virtual machines from one location to another location is reconfiguring the network so that the VMs can communicate on the new network that most likely is configured at the new location. IP address space that is used in the production site are most likely different than the IP address space in the secondary/DR facility. Additionally virtual switch labels, VLANs, and such are most likely different as well.
This means that via manual or automated means, the network configuration on the virtual machines being replicated would need to be reconfigured during a failover event to match and align with what needs configured for successful serving out of traffic in the secondary/DR location.
Configuring Effective VM Replication
Using a data protection solution is one of the best and easiest ways toProtect VMs at the Site-Level with VM Replication. Many modern data protection solutions will have the ability to not only back up virtual machines but also replicate virtual machines from one site to another site for site-level resiliency.
One of the key features that you want to look for is the ability to perform automated network configuration. In the case of VMware, this is done by interacting with VMware Tools to reconfigure the network settings for the new location. As a virtual machine that has been replicated from production over to a secondary/DR site is powered on and boots, the data protection solution reconfigures the network settings to match the DR environment.
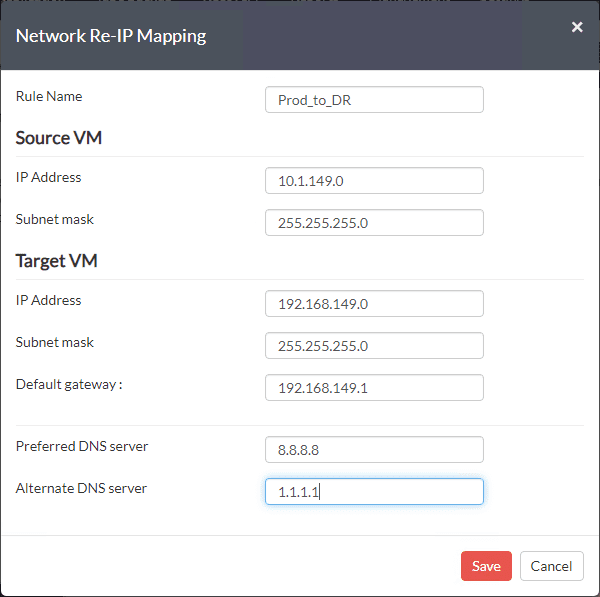
Below is an example of using Vembu BDR Suite for creating a replication job to replicate virtual machines from production to DR and reconfiguring the network in the same process. Note how Vembu allows you to “map” the virtual network in prod to the one you want to connect the VM to in the secondary facility/DR facility. Additionally, you can create a mapping up IP addresses from the one to the other.
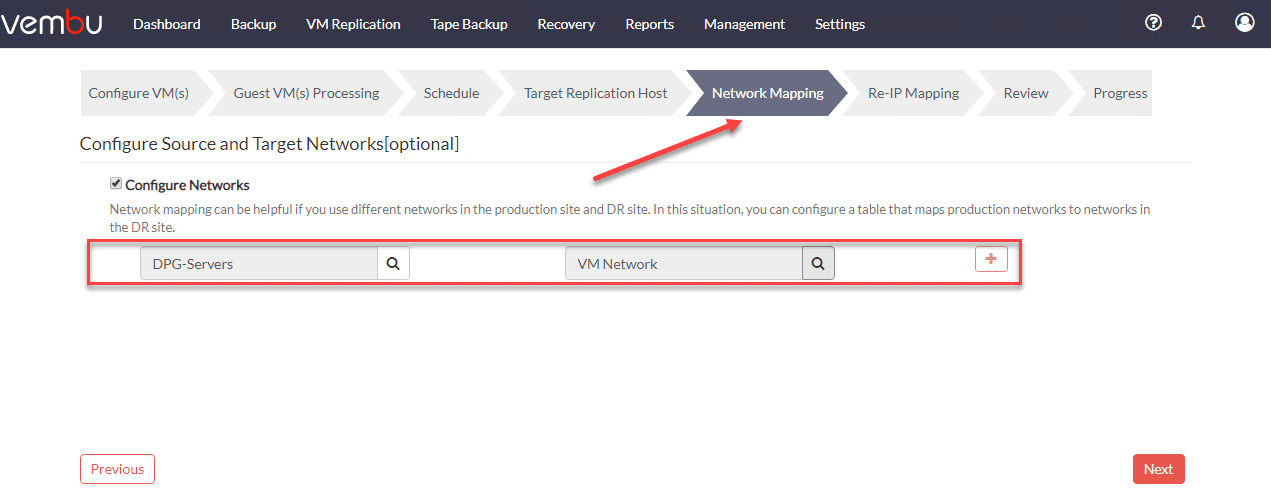
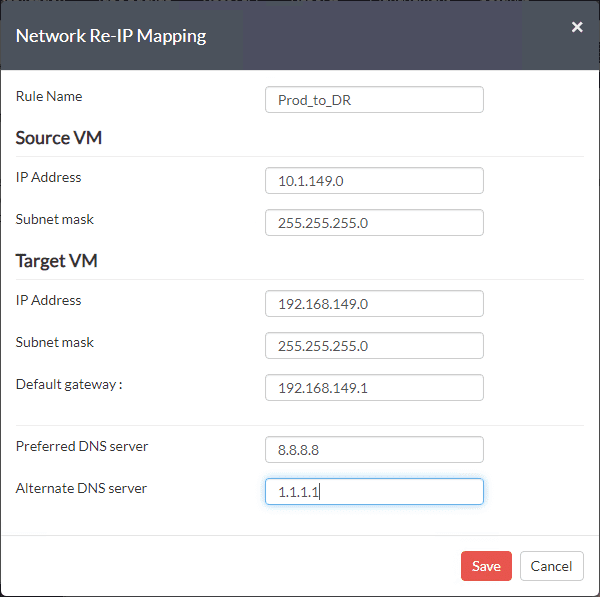
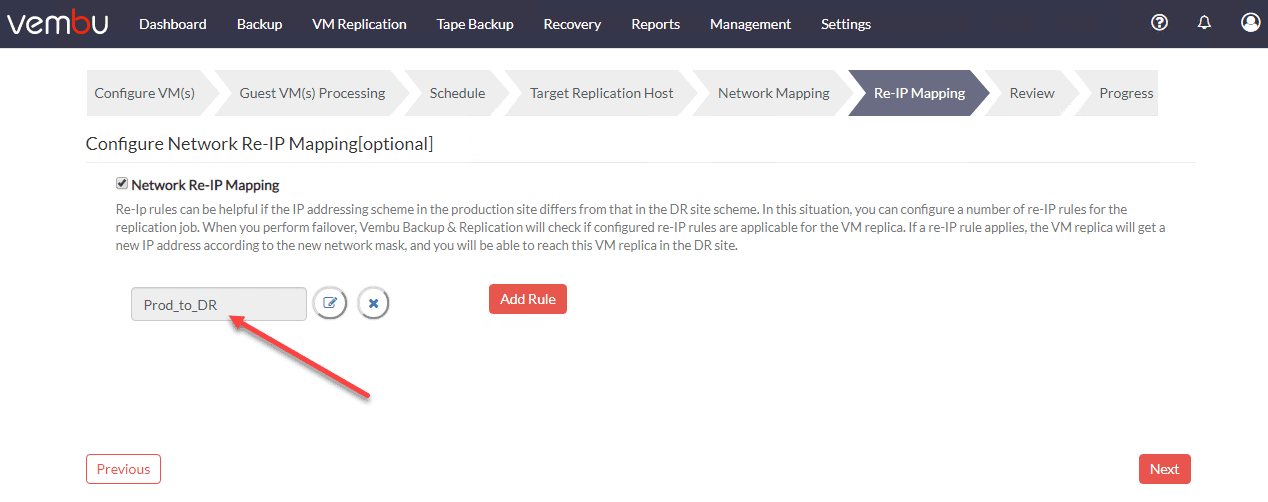
Wrapping Up
A major part of an effective disaster recovery strategy is to protect VMs at the Site-Level with VM Replication. This includes having the ability to failover from one site to another. Having an automated means by using a data protection solution is a great way to perform the very tedious network configuration to reconfigure VMs from one site to another during a disaster.
For the recovery of your data and to ensure business continuity, VM replication is an integral part of an overall disaster recovery strategy. Additionally, automated network reconfiguration is an essential component that allows easily reconfiguring network settings on virtual machines coming from production and failed over in a DR environment.