VMware vSAN Home Lab Hardware Failure and Resiliency
I have been running a VMware vSAN based home lab environment for the past year or so now. It has performed and worked flawlessly since instantiating the 2-node vSAN cluster a little over a year ago. The cluster is completely NVMe based storage which makes for an extremely performant environment relatively cheaply. I am constantly surprised at how cheap NVMe storage has gotten, even since a year ago when I purchased the additional drives needed for my cluster. However, I finally experienced a hardware failure in my VMware vSAN home lab environment. Over the past weekend at the time of this writing, a cache drive in one of my ESXi nodes bit the dust. I performed the normal troubleshooting with the NVMe stick, powering off, and reseating as well as a few other tricks. However, the drive simply shows to be dead and not recognized. I have a new drive ordered and on the way as we speak. I was pleasantly surprised at how well the vSAN cluster handled the error and continued to serve out my VMs. My VMware vSAN home lab hardware failure and resiliency of the solution increased served to bolster my already confident trust in vSAN as a platform for enterprise production workloads. I want to walk through the series of events that led up to discovering the hardware failure in vSAN and how the system handled the degradation in the drives. Let’s look at VMware vSAN Home Lab Hardware Failure and Resiliency.
VMware vSAN Drive Errors
I started receiving errors in the data protection solution covering the home lab environment that there were unusable disks in the vSAN cluster and less than the number of fault domains required. This all indicated that something bad had happened in the environment. So, off to checking vSphere client to see what had happened.
In the vSphere client, I saw the error for VM snapshot creation – “There are currently 1 usable disks for the operation. This operation requires 1 more usable disks. Remaining 1 disks not usuable because: 0 – Insufficient space for data/cache reservation. 0“.
In looking at the Configure > vSAN > Disk Management section, I see the cache disk is showing up as Dead or Error.
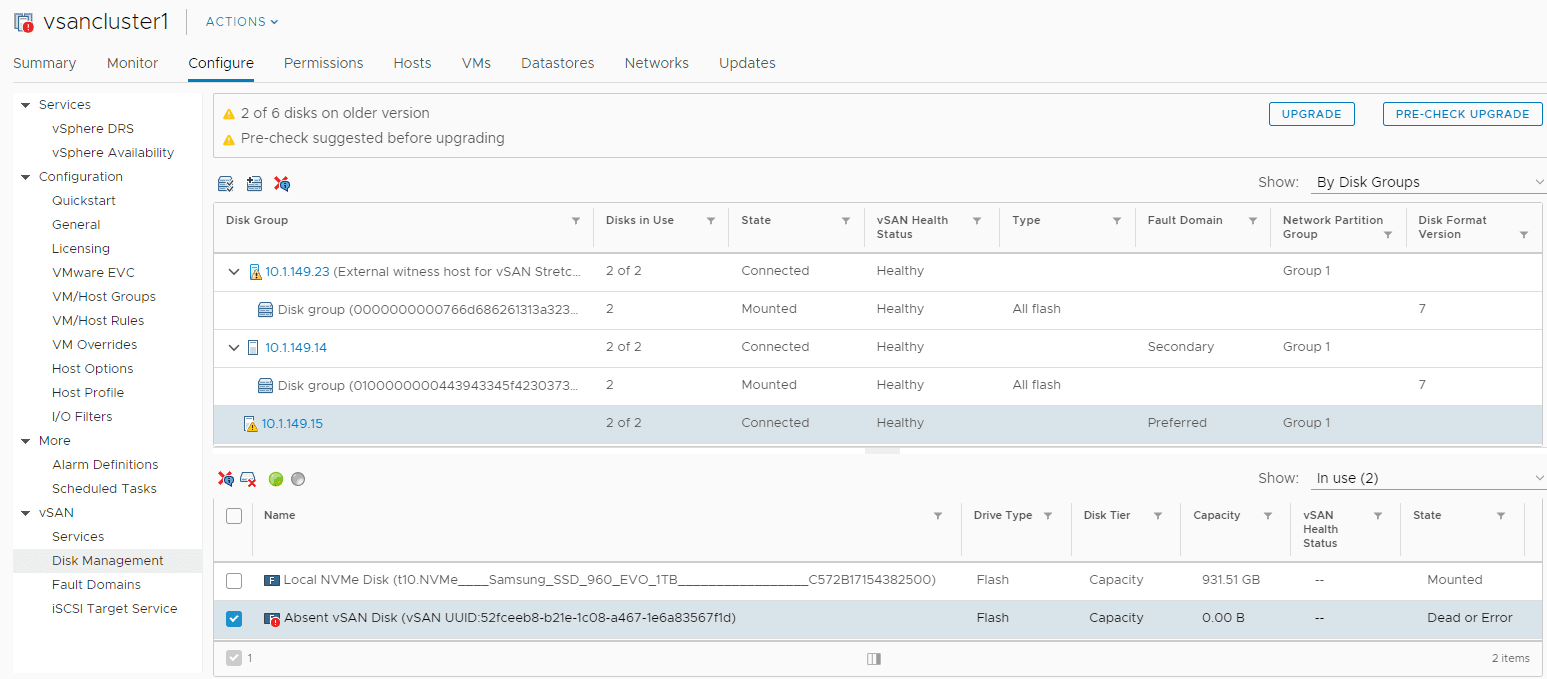
At this point, I did all of the typical troubleshooting such as placing the server in maintenance mode, rebooting, and checking out the disk. After a reboot, I actually did see the disk come up briefly. Upon attempting to start a VM on the host however, the disk quickly went back into an error state.
Next, a shutdown of the host. I reseated the NVMe stick just to cover the bases. After rebooting, the drive was still showing up as dead.
A quick aside here. At this point, I still have all my VMs running on a single host that still has availability to the vSAN datastore and no issues with VM availability. Ironically for me, I was doing some black Friday shopping for another NVMe drive to create a standalone datastore on my second host for nested vSAN environment testing and a few other use cases. The Samsung 970 drives are super cheap. The timing was right so I decided to snag not only a datstore drive, but another cache disk for use to replace the failed NVMe drive.
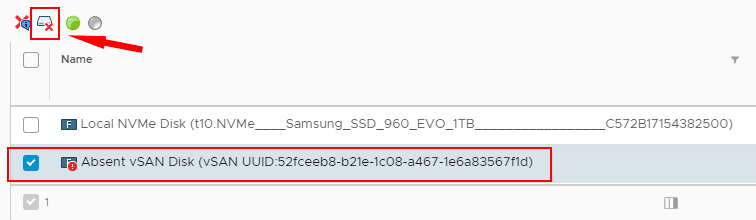
Removing the failed NVMe cache disk
The procedure is well documented from the KB Remove Disk Groups or Devices from vSAN.
Procedure
- Click Yes or Delete to confirm.
The data is evacuated from the selected devices or a disk group and is no longer available to vSAN.

A few points of observation with VMware vSAN and a cache disk failure.
- The capacity drive on the failed host’s disk group continued to function and offer capacity to vSAN without the cache drive. I saw this as even with the cache disk dead, vSAN was still showing the full capacity.
- Removing the cache drive will remove your disk group from the server. You might think that you can leave the disk group intact when replacing/removing a cache drive. However, it is expected behavior that removing a cache drive will remove the disk group from the server. This is taken directly from the VMware KB Remove Disk Groups or Devices from vSAN. As mentioned in the KB: “Removing one flash cache device or all capacity devices from a disk group removes the entire disk group.”
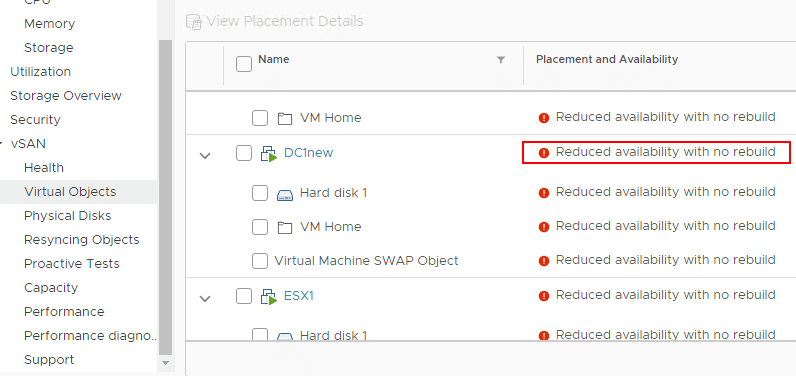
- Another point to note – Evacuating data from devices or disk groups might result in the temporary noncompliance of virtual machine storage policies. You can see this below. If you look under the Monitor > vSAN > Virtual Objects dashboard, you will see the VMs that are impacted.
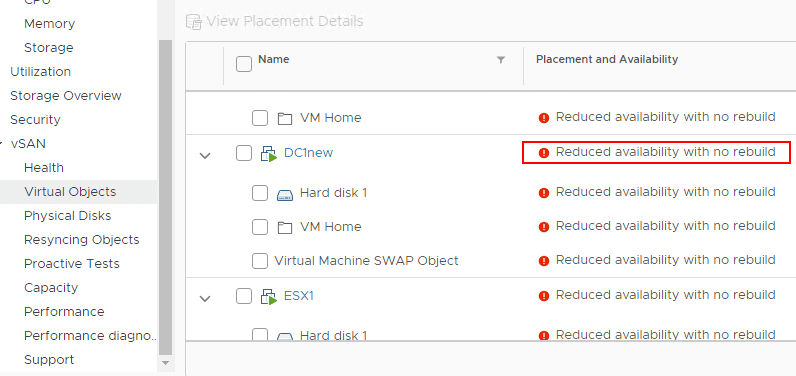
For my lab environment, I am sitting in a state of reduced availability with no rebuild, however, VMs are running fine and so far have not had any disruption. A new Samsung 970 should arrive today. Will be documenting how the process to replace the drive and reprovision the disk group in the next post 🙂
Takeaways
My first VMware vSAN Home Lab Hardware Failure and Resiliency test so far is going well. VMware vSAN has withstood the hardware failure very well and virtual machines are running without issue. For me, it is a testament to the fact that software-defined infrastructure is resilient and certainly able to run production workloads in a way that leads to confidence in the solution. Stay tuned for more information on my lab failure and the changing out of the cache drive with a new cache drive arriving soon. Until then, my vSAN environment is chugging away, albeit with reduced availability.